Paper Insights #23 - Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases
The previous insight provided sufficient context for building a distributed SQL database using two-phase commit (2PC). However, before doing so, we will explore Amazon Aurora, a distributed SQL database that intentionally avoids 2PC.
This paper was published in 2017 and presented at the SIGMOD (Special Interest Group on Management of Data) conference by Alexandre Verbitsky et al. It presents a clever approach that enables distributed SQL functionality without the need for 2PC - a concept that may initially seem counterintuitive.
In this insight, we will begin by reviewing some foundational cloud computing concepts. We will then dig deeper into data replication and the various techniques used to achieve it. This will be followed by a revisit of the core concepts behind SQL databases before performing a comprehensive deep dive into Aurora’s architecture.
Recommended Read: Paper Insights - A New Presumed Commit Optimization for Two Phase Commit where 2PC was introduced.
1. Cloud-Native
The term "cloud-native" gained prominence in the late 2000s as cloud computing adoption accelerated.
Cloud-native refers to a methodology for building and running applications that fully leverages the distributed computing and scalability capabilities of cloud environments. It focuses on how applications are designed and deployed, not simply where they reside.
Aurora is a cloud-native database service, meaning it's constructed entirely from cloud components. Let's briefly cover the relevant AWS cloud services:
- EC2 (Elastic Compute Cloud): Virtual machines in the cloud.
- S3 (Simple Storage Service): Cloud object storage where data is stored as objects, each identified by a key. Object sizes can range from kilobytes to gigabytes. (For related reading, consider exploring Paper Insights - Delta Lake: High Performance ACID Table Storage over Cloud Object Stores.)
- EBS (Elastic Block Store): Provides block storage volumes that can be attached to EC2 instances.
2. Clusters & Availability Zone
A cluster is a group of interconnected computers, typically using high-bandwidth fabric networks. These clusters are often hosted within data centers.
Availability Zones (AZs) are distinct physical locations within a specific geographic region. Think of them as individual data centers, potentially composed of multiple machine clusters. AZs are themselves contained within a larger geographic region. As of February 2025, AWS Cloud spans 114 Availability Zones within 36 geographic regions. For example, the us-east-1 region includes AZs like use1-az1, use1-az2, and so on (complete list).
An AZ, or even an entire region, can become unavailable due to various factors such as natural disasters, network outages, and planned maintenance or repairs. Therefore, robust services must be replicated across multiple AZs and regions.
3. Correlated Failures
Operating System Bugs: An OS bug can impact numerous machines within a cluster or even an entire availability zone. This highlights the importance of staged rollouts for OS upgrades: first a small set of machines, then a canary group, and finally, a broader deployment.
-
Hard Drive Failures: A manufacturing defect in a batch of hard drives can lead to simultaneous failures across availability zones where those drives were deployed. Mitigation strategies include staggered hard drive replacements and using drives from different batches or manufacturers within a data center.
-
Network Switch Failures: Servers are often organized into racks, with multiple machines connected within each rack. Communication between machines in different racks requires traversing a network switch. A failure of this switch can impact all machines within the affected rack. Therefore, when replicating data within a cluster, it's essential to ensure that each replica resides on a different rack. Ideally, no two replicas of the same data should be on machines within the same rack.
-
Natural Disasters (Fire, etc.): These can incapacitate an entire availability zone or even a region.
-
Power Outages: These can also take down an availability zone.
-
Undersea Cable Cuts: In a worst-case scenario, an undersea cable cut can render an entire region unavailable.
3.2. Mean Time To Failure
3.3. Mean Time To Repair
3.4. Double Fault
4. Replication
Replication involves creating multiple copies of the same data, typically key-value pairs where the key identifies the value. The value itself is replicated across multiple machines. Maintaining consistency across these replicas is crucial, and several algorithms address this.
4.1. Primary-Secondary Replication
One replica is designated the primary, and all writes are directed to it. The primary then propagates these writes to the secondary replicas, often asynchronously, as shown in illustration 1. Relaxed reads at the secondaries can improve performance. This can be extended to multi-primary setups.

Illustration 1: Primary-secondary replication.
4.2. Leaderless Replication (Quorum)
All replicas are equivalent. Each item has a version number that increments with each write. For a majority, at least N / 2 + 1 replicas must participate in both writes and reads at the same version number, as shown in illustration 2:
- Writes: The client sends writes to all N replicas. An acknowledgment is sent when N / 2 + 1 replicas have committed the write.
- Reads: The client queries N / 2 + 1 replicas. At least one of these will have the latest value, ensuring consistency.

- Paper Insights - Dynamo: Amazon's Highly Available Key-value Store for more details on how Dynamo achieves replication using quorum.
- Paper Insights - Practical Uses of Synchronized Clocks in Distributed Systems for more details on how Harp replication works.
4.3. Chain Replication
In chain replication, replicas are arranged in a chain, as shown in illustration 3. All writes are sent to the head, and the tail sends the final acknowledgment. Each node commits the write and forwards it to the next node in the chain. Each node has more information than its successor but less than its predecessor.

- If the head fails, the next node in the chain becomes the head. Pending writes are dropped because they were not yet committed.
- If a middle node fails, the two adjacent nodes connect with each other. Pending writes are propagated again from the point of failure.
- If the tail fails, its predecessor becomes the tail.
Consistent reads must go to the tail, as that's where the committed value resides.
Advantages: Lower network usage compared to quorum-based approaches, as clients don't need to send data to W members.
Disadvantages: Higher latency due to the sequential nature of writes.
Delta is one example of an implementation of chain replication.
5. Relational (SQL) Databases
- Atomicity: A transaction either completes entirely or not at all. No partial updates are allowed.
- Consistency: Transactions maintain database integrity by adhering to all defined constraints. The database remains in a valid state before and after each transaction.
- Isolation: Transactions appear to execute independently, as if they were the only ones running. Different isolation levels exist, with serializable isolation ensuring transactions appear to occur in a specific serial order.
- Durability: Once a transaction is committed, the changes are permanent and survive even system failures.
- Atomicity ensures both the debit from A and the credit to B occur, or neither does.
- Consistency ensures the total balance across all accounts remains constant.
- Locks: Data items (rows, cells) are locked in shared (read) or exclusive (write) mode to prevent conflicting modifications.
- Version Numbers: Data items are versioned, and modifications create new versions, allowing reads to occur on older versions while writes happen on newer ones.
5.1. REDO Logs
- [start, TID]: Transaction TID has begun.
- [write, TID, X, new_value]: Transaction TID wrote new_value to data item X.
- [commit, TID]: Transaction TID committed successfully.
- [abort, TID]: Transaction TID was aborted.
5.2. Popular SQL databases
- MySQL: A widely used, open-source relational database known for its ease of use and reliability, making it a popular choice for web applications.
- PostgreSQL: Another powerful open-source relational database, known for its extensibility and adherence to SQL standards. It's often preferred for applications requiring complex data management and analysis.
- Microsoft SQL Server: A robust relational database developed by Microsoft, commonly used in enterprise environments for high-volume transaction processing and business intelligence.
- SQLite: A lightweight, serverless relational database that's embedded within applications. It's often used for mobile apps and small-scale projects.
6. Distributed Relational (SQL) Databases
A distributed SQL database stores data across multiple servers, potentially geographically dispersed. This partitioning also applies to transaction logs. Building such a system requires sophisticated algorithms, such as two-phase commit (2PC).
Distributing a database is a notoriously difficult problem in computer science. Google's Spanner tackled this by distributing the entire database engine, relying heavily on 2PC. While 2PC can be slow and limit throughput, Spanner's use of TrueTime enabled it to achieve reasonable performance, making it a unique example of a true distributed database.
Aurora, however, took a different approach. It is a distributed RDBMS that achieves distribution without using 2PC. The next section will explore how Aurora accomplishes this.
7. Aurora
Aurora avoids distributing the database engine itself. Instead, it relies on replicating transaction logs. Since the transaction log effectively is the database (as it can be used to rebuild the database state), distributing the log achieves the desired distribution.
Aurora uses a three-server setup for each database: a primary instance that handles all transactions, and two secondary replicas that maintain copies of the database. The secondaries receive asynchronous updates from the primary after a transaction commits.
Each instance is a fully functional, independent SQL database server (e.g., MySQL).
Therefore, Aurora's approach differs from traditional distributed SQL databases. The transaction execution) occurs on a single node (the primary). What makes Aurora "globally available" is the distributed replication of the transaction logs.
Let's delve deeper, but first, let's address some common questions:
7.1. FAQ
- Doesn't distributed SQL require 2PC? Yes, true distributed SQL databases do. However, Aurora's SQL engine itself is not distributed. Only the transaction logs are.
- Is consensus required for transaction log replication? No. Consensus is used to build distributed logs, where each entry represents a value agreed upon by multiple participants. In Aurora, the transaction log entries are determined by the single primary SQL instance. The underlying system's job is simply to replicate these pre-determined entries. Simple quorum replication is sufficient for this purpose.
7.2. Naive Approach to Transaction Log Replication
A key goal in Aurora is replicating the transaction logs generated by the SQL engine. A naive approach, as described in the paper, involves the following steps:
- Write logs to EBS.
- EBS mirrors the logs (using software mirroring).
- Forward the modifications to the replica SQL engine instance.
- Write logs to the replica instance's EBS.
- Replica instance's EBS mirrors the logs.
The paper also mentions additional logs, such as binary logs, stored in S3. Crucially, steps 1, 3, and 5 are sequential. A transaction cannot commit without the initial write to EBS (step 1). Replication cannot begin before the commit (and thus step 1). Similarly, the replica's EBS mirroring (step 5) cannot start before the logs are written to the replica's EBS (step 4, which is dependent on step 3).
These sequential dependencies introduce latency and excessive write operations.
8. Aurora's Architecture
Aurora employs a service-oriented architecture (SOA), separating compute and storage layers, as shown in figure 3. This contrasts with a shared-nothing architecture. The storage layer handles transaction log storage, materialization, and replication, while the compute layer hosts the SQL engine instances.
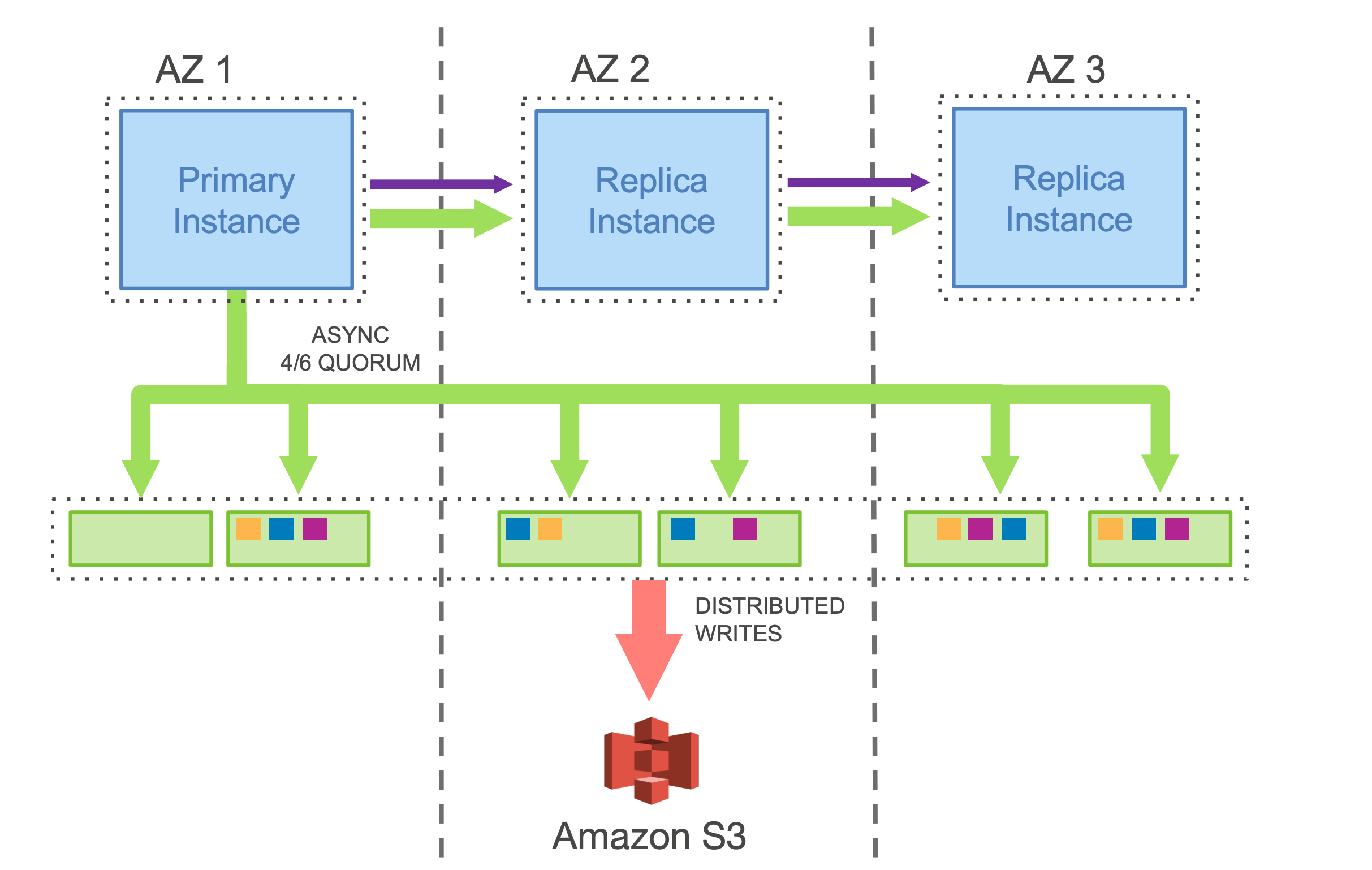
Figure 3: Copy of figure 3 from the paper.
8.1. Compute
The compute layer consists of three instances across different availability zones. The primary SQL engine resides in one zone, and REDO logs are forwarded to the other two replicas using chain replication, although, in this case, the ack is sent by the primary instance itself and the replication is asynchronous.
8.2. Storage
The storage layer maintains six replicas of each log entry, with two replicas per availability zone. Replication is quorum-based, with a write quorum (W) of 4 and read quorum (R) of 3. The primary compute instance is responsible for replicating log entries, and an entry is considered committed once four out of the six replicas acknowledge receipt.
For performance reasons, all input/output operations are handled in batches. The storage layer's internal workings are more intricate, and further details can be found in section 3.3 of the paper.
9. Data Partitioning
The database volume is divided into 10GB segments. The SQL engines cache these segments, which hold the actual data. Each segment is replicated six ways in the storage layer. These replicated segments are called Protection Groups (PGs).
Each segment stores multiple pages of the database. A page is the smallest unit of data that the database reads from or writes to storage at one time. It's a block of contiguous memory. The compute instances caches the database pages in the buffer cache. Upon miss, the database page is read from the storage.
For each page, the primary compute instance maintains the following metadata:
- The highest log entry number that modified the page. Since the primary commits log entries, it knows which entry last updated a given segment.
- The storage nodes that have a complete, materialized version of the page. As the primary receives acknowledgments from the storage replicas after writes, it tracks which storage nodes have all updates for each page.
10. Transaction Logs
10.1. Log Structure
Log records in Aurora are assigned a Log Sequence Number (LSN). Because the SQL engine is a single instance, log entries are pre-determined, eliminating the need for 2PC or consensus during replication. Log entries are simply replicated using Quorum. Additionally, those replicas that may miss an entry will receive it through gossip protocols.
Two important LSN values are tracked:
- Volume Complete LSN (VCL): The storage service guarantees log availability up to VCL. Log entries with LSNs higher than the VCL are not guaranteed to be available and can be discarded.
- Volume Durable LSN (VDL): The highest LSN for which the SQL engine guarantees database consistency. The VDL must be less than or equal to the VCL.
The VCL and VDL are independent because the compute and storage layers operate independently. The VCL is a storage layer concept related to log availability guarantees. The VDL is a compute layer concept, built upon the VCL, that guarantees database consistency up to that point.
When a new log entry is added, an LSN is generated using the current VDL and an upper bound called the LSN Allocation Limit (LAL). The LAL limits how far LSNs can advance ahead of database consistency points, i.e., VDL.
While data is segmented, Aurora maintains a single, globally ordered transaction log. Each log entry includes a back pointer to the previous log entry relevant to a specific segment. These back pointers enable the system to efficiently identify all log entries associated with a given segment.
A key concept related to segments and logs is the Segment Complete LSN (SCL). SCL indicates the point at which all log records for a particular replica of a segment are complete. This is used in gossip protocol to exchange log records.
10.2. Log Materialization
The storage layer not only stores transaction logs but also independently materializes them into database pages in the background. These materialized pages might not always be the most up-to-date version; new updates can be applied to them to reflect the latest state.
11. Transaction Processing
All transactions are executed by the primary instance. Since the primary cannot hold all database pages in memory, cache misses can occur. When a cache miss happens, the primary requests the complete page from a storage node that has it.
Critically, remember that there's only one primary SQL instance. All transactions flow through it. This means the primary always knows the highest sequence number that modified any given page.
The transaction flow is as follows:
- The primary computes state updates (writes).
- The primary writes the logs to the storage layer.
- The primary waits for a write quorum from the storage nodes.
- Storage nodes acknowledge as soon as the log is committed.
- The primary sends REDO logs to the replica SQL instances.
The VDL advances as logs are written and acknowledged. Once the VDL advances past the commit log entry for a transaction, the primary sends an acknowledgment back to the client, confirming the transaction's completion.
12. Reads
Reads in Aurora are typically served from the buffer cache. A storage fetch is only necessary when the buffer cache lacks the requested page. Pages in the buffer cache are guaranteed to be the latest version, ensured by evicting a page only if its LSN is greater than or equal to the current VDL.
Aurora offers different read consistency levels:
-
Strong Reads (Serialized/Transactional Reads): These reads are routed to the primary instance to guarantee the latest data, as the primary is the only instance fully up-to-date. Note that the SQL engine must also operate in serializable isolation mode to support these reads.
-
Relaxed Reads: These reads can return slightly stale data. They can be served from any replica instance, which typically lag behind the primary by around 20ms. Replicas asynchronously consume log records with LSNs less than or equal to their respective VDLs.
-
Point-in-Time Reads: These reads retrieve data as it existed at a specific LSN (the read point). This ensures the data is at least as current as the read point. The database can serve these reads from storage replicas whose page VDL meet or exceed the specified read point.
Finally, each segment has a per-PG Minimum Read Point LSN (PGMRPL). This is the lowest LSN at which reads for that segment are in-process. The database maintains this value, which acts as a lower watermark. Log records older than the PGMRPL are no longer needed, allowing the storage layer to materialize pages up to the PGMRPL and garbage collect older log records.
13. Recovery
The storage layer handles log application, meaning the SQL engine doesn't need to replay logs after a crash. Upon recovery, the primary simply needs to recompute the VDL from the storage layer and resume logging new transactions from that point. The paper reports a recovery time of approximately 10 seconds.
14. Administration
Aurora has high fault tolerance:
- Writes to storage remain available even if an entire AZ goes down.
- Reads are possible with the loss of a single AZ. Furthermore, Aurora can withstand an additional failure affecting a subset of machines in another AZ, such as a switch failure.
Aurora's design simplifies administration in several ways:
-
Software Upgrades: The fast recovery times enable zero-downtime patching. Because all state is persisted in the storage layer's logs, the compute layer can simply wait for active transactions to complete before restarting with the updated software (e.g., a new binary).
-
Simplified Storage Management: There's no need to shut down SQL machines to update storage or adjust disk usage.
15. Evaluation
- Aurora's read and write throughput scales linearly with instance size, which is expected given the increased processing capacity of larger instances.
- Aurora demonstrates significantly higher throughput than MySQL, likely due to its sophisticated storage layer and batching mechanisms (though the specific reasons require further investigation). A comparison of latency under the same test conditions could have been valuable.
- Replica lag in Aurora is influenced by the write rate on the primary. In one test, a write rate of 10,000 writes/sec resulted in a replica lag of only 5.38ms. This is substantially lower than naive MySQL's replication lag, which reached 300s.
16. Paper Remarks
This paper is quite readable. The concepts are straightforward, especially once the design's niche is understood: the transaction log is the database. Global availability is simply achieved through transaction log replication. The paper also serves as an excellent resource for learning fundamental cloud computing concepts and operational details, providing practical insights into how cloud systems are managed.
Comments
Post a Comment